Introducing BentoML 1.2
February 20, 2024 • Written By Sean Sheng
Introduction
It's been more than a year since we launched BentoML 1.0, and during that time, we've learned a lot. We've taken the opportunity to incorporate all these learnings in our latest open-source release and today we're thrilled to unveil it - BentoML 1.2! In this update, you'll discover exciting evolutions in the Bento Service SDK, improvements in deployment workflows, a brand new BentoCloud web UI, along with enhanced Bento client support. Before we dive in, we want to reassure you that this release maintains full backward compatibility. All the features you trust and love, such as Bento packaging and containerization, multi-modal inference graph, and adaptive batching, are still there at your disposal. With that, let's get started!
Simplified Service SDK
Earlier versions of BentoML aimed at simplifying the integration of ML frameworks. This was achieved through out-of-box integrations with frameworks like PyTorch and TensorFlow. These integrations allowed developers to load models built with these frameworks using a single line of code. However, as the landscape of machine learning (ML) evolved, particularly in the areas of Large Language Models (LLMs) and Generative AI, the existing approach became less optimal. Innovations in libraries like vLLM, Transformers, Diffusers, and PyTorch 2.0 brought significant enhancements in the performance of model inference, underscoring the need for a more flexible and adaptable approach.
BentoML 1.2 focuses on empowering developers with greater control and flexibility. The new framework uses familiar Python constructs, enabling Services to be defined as classes and APIs as functions. Developers can now initialize models in the Service constructor and embed inference logic in API functions. This approach offers a clearer and more intuitive Service interface, allowing developers to add custom logic and use third party libraries with ease. The example below demonstrates the flexibility of the Service API by initializing a vLLM AsyncEngine in the Service constructor and run inference with continuous batching in the Service API.
@bentoml.service( traffic={ "timeout": 300, }, resources={ "gpu": 1, "gpu_type": "nvidia-l4", }, ) class VLLM: def __init__(self) -> None: from vllm import AsyncEngineArgs, AsyncLLMEngine ENGINE_ARGS = AsyncEngineArgs( model='meta-llama/Llama-2-7b-chat-hf', max_model_len=MAX_TOKENS ) self.engine = AsyncLLMEngine.from_engine_args(ENGINE_ARGS) @bentoml.api async def generate( self, prompt: str = "Explain superconductors like I'm five years old", max_tokens: Annotated[int, Ge(128), Le(MAX_TOKENS)] = MAX_TOKENS, ) -> AsyncGenerator[str, None]: from vllm import SamplingParams SAMPLING_PARAM = SamplingParams(max_tokens=max_tokens) prompt = PROMPT_TEMPLATE.format(user_prompt=prompt) stream = await self.engine.add_request(uuid.uuid4().hex, prompt, SAMPLING_PARAM) cursor = 0 async for request_output in stream: text = request_output.outputs[0].text yield text[cursor:] cursor = len(text)
Another significant change in this release is how it handles configuration. Instead of using separate YAML files, configurations are now part of the Python module, close to where the Service is defined. By using the @bentoml.service decorator, all the configurations related to the Service can be placed right where the Service class is. This makes managing configurations more straightforward.
The distributed runner architecture, a popular feature in previous versions of BentoML, has also received an upgrade. This architecture allowed models to be deployed independently, running on dedicated instance types, and scaling independently. In BentoML 1.2, this concept has expanded through the introduction of a Service-dependent graph. This new feature allows the definition of multiple Services within a BentoML project, with Services declaring their dependencies using the bentoml.depends function. Services can then interact with their remote dependencies using simple Python function calls in their API functions. When deployed, each Service operates on its designated instance type and scales independently of other Services.
In the multi-Service example below, each of the LLMService, SDXLTurboService, and XTTSService runs their corresponding models independently in their own Services. The GreetingCardService declares dependencies on these Services in the class and invokes them in the API function. The syntax of the invocations to these Services are identical to Python function calls and they can be done either sequentially or in parallel. The underlying framework handles the routing and Service discovery automatically. Each Service is deployed on the most optimal instance type and scales independently, adapting to the workload demands triggered by these invocations.
@bentoml.service class LLMService: ... @bentoml.service class SDXLTurboService: ... @bentoml.service class XTTSService: ... @bentoml.service( traffic={"timeout": 600}, workers=4, resources={"cpu": "1", "memory": "4Gi"}, ) class GreetingCardService: llm = bentoml.depends(LLMService) sdxl = bentoml.depends(SDXLTurboService) xtts = bentoml.depends(XTTSService) @bentoml.api async def generate_card( self, context: bentoml.Context, message: str = "Happy new year!", ) -> Annotated[Path, bentoml.validators.ContentType("video/*")]: greeting_message = await self.stablelm.enhance_message(message) sdxl_prompt_tmpl = "a happy and heart-warming greeting card based on greeting message {message}" sdxl_prompt = sdxl_prompt_tmpl.format(message=greeting_message) audio_path, image = await asyncio.gather( self.xtts.synthesize(greeting_message), self.sdxl.txt2img(sdxl_prompt) ) image_path = os.path.join(context.directory, "output.png") image.save(image_path) cmd = ["ffmpeg", "-loop", "1", "-i", str(image_path), "-i", str(audio_path), "-shortest"] output_path = os.path.join(context.directory, "output.mp4") cmd.append(output_path) subprocess.run(cmd) return Path(output_path)
Familiar input and output types
In earlier versions of BentoML, defining input and output types and their behaviors required using parameters in the API decorator. This method, while offering flexibility, had its challenges. As the number of parameters grew or their schema became more complex, the definition process could become cumbersome.
BentoML 1.2 introduces a significant simplification in this approach. Now, developers can employ familiar Pythonic types directly, without the need for additional definitions or decorations. Standard primitive types such as str, float, list, and dict can be seamlessly used into API definitions. For those accustomed to building APIs in Python, Pydantic's integration into BentoML 1.2 will be a welcome feature. This inclusion means that all types supported by Pydantic can now be used in defining BentoML APIs directly. Pydantic's robust validation capabilities are now inherent in BentoML, ensuring that API inputs and outputs adhere to expected formats and standards.
Recognizing the specific needs of ML applications, BentoML 1.2 has expanded its type support to include those frequently used in ML contexts. This includes types for tensors, such as numpy.ndarray and torch.Tensor, and tabular data like pd.DataFrame. These types allow developers to define APIs that directly handle complex data structures common in machine learning, with BentoML handling the serialization and validation. Among these types, an exciting addition in BentoML 1.2 is the introduction of the pathlib.Path type. This type is especially useful in Generative AI applications, where inputs and outputs often include media files. Using the Path type, developers can interact with file inputs and outputs directly, simplifying the process of managing file-based data and eliminating the complexities of file serialization and deserialization.
In the WhisperX example below, input audio can be treated exactly like a file using pathlib.Path input type, enabling directly copy-and-pasting the script from the official WhisperX documentation. Using audio file directly saves the effort of developers having to learn how to deserialize binary wire formats. The underlying framework will serialize and deserialize files safely and efficiently.
@bentoml.service( traffic={"timeout": 30}, resources={ "gpu": 1, "memory": "8Gi", }, ) class WhisperX: """ This class is inspired by the implementation shown in the whisperX project. Source: https://github.com/m-bain/whisperX """ def __init__(self): import torch import whisperx self.batch_size = 16 # reduce if low on GPU mem self.device = "cuda" if torch.cuda.is_available() else "cpu" compute_type = "float16" if torch.cuda.is_available() else "int8" self.model = whisperx.load_model("large-v2", self.device, compute_type=compute_type, language=LANGUAGE_CODE) self.model_a, self.metadata = whisperx.load_align_model(language_code=LANGUAGE_CODE, device=self.device) @bentoml.api def transcribe(self, audio_file: Path) -> t.Dict: import whisperx audio = whisperx.load_audio(audio_file) result = self.model.transcribe(audio, batch_size=self.batch_size) result = whisperx.align(result["segments"], self.model_a, self.metadata, audio, self.device, return_char_alignments=False) return result
Deployment that just works
In the latest release of BentoML, a key enhancement has been made in the deployment process, simplifying it significantly. Before 1.2, deploying a Bento involved a multi-step procedure that could be somewhat burdensome. The process required developers to first build their project into a Bento, then push this Bento to BentoCloud, and finally deploy it using the BentoCloud console. This workflow, while functional, was recognized as more complex than ideal.
This release of BentoML streamlines the deployment workflow to allow more rapid development iterations and a faster time to production by enabling the ability to directly deploy to BentoCloud from a project on the command line. This eliminates the need for the previously mandatory steps of building and pushing the Bento before deployment. Developers can now simply execute the command bentoml deploy . in their terminal. This command automatically handles the tasks of building, pushing, and deploying the Bento, effectively consolidating the entire deployment process into a single, straightforward step.
Deployment can also be initiated and updated directly from a Python script. This capability is particularly advantageous for facilitating continuous integration and deployment in projects. Moreover, scheduled jobs can utilize the Python deployment API, enabling the deployment of a Bento before the commencement of a job and its subsequent undeployment upon completion, thereby optimizing costs.
Intuitive web UI and client
While APIs are powerful, what we learned in the past year is that a web UI is the best interface for demonstrating and troubleshooting an ML application. The complex input and output types required by ML applications have outgrown the capabilities of the Swagger interface provided by BentoML. There's a growing demand for a more dynamic UI that adapts based on the API. BentoML 1.2 introduces a new feature: all Bentos are now accompanied by a custom-generated UI in the BentoCloud Playground, tailored to their API definitions. This enhancement offers developers a more engaging and interactive experience with their APIs, making the process not just more intuitive but enjoyable as well.
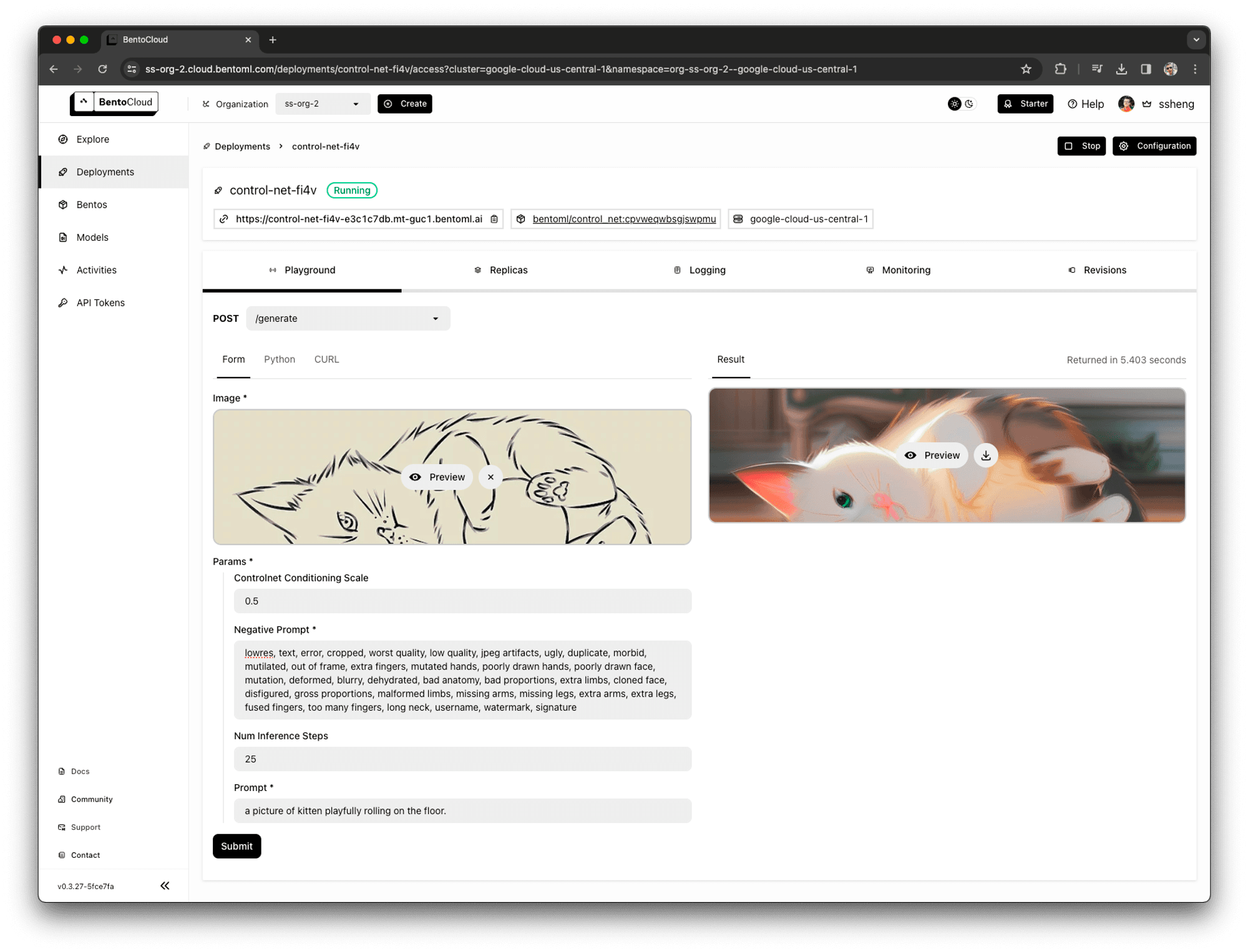
Generated web UI for a ControlNet model that accepts a control image and a list of schematized parameters, such as prompt, negative prompt, and inference steps, returns an image.
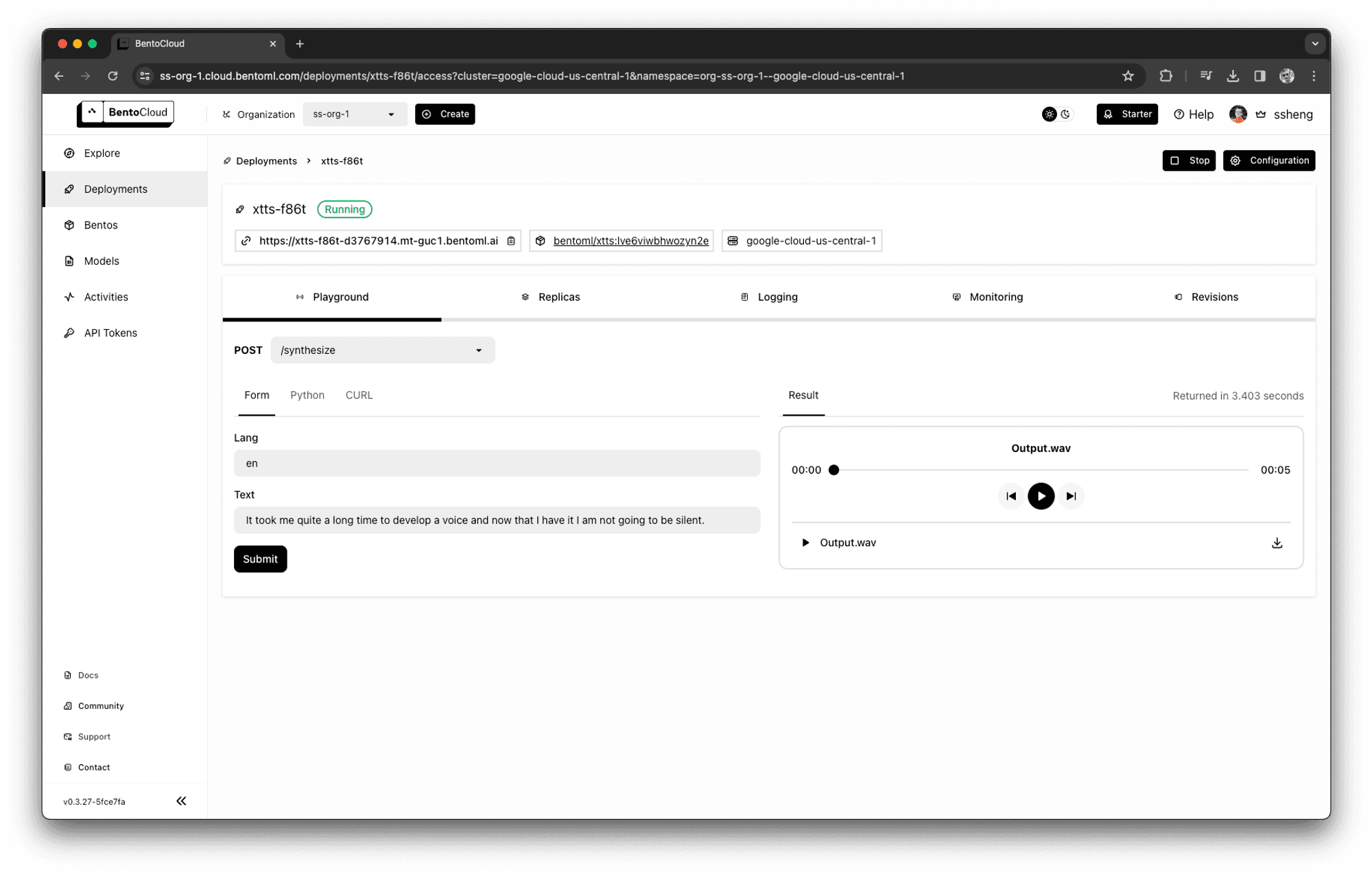
Generated web UI for an XTTS model that accepts a language code and text, and return a waveform audio.
In addition to offering a user-friendly interface, it's crucial to ensure easy API interactions. After all, the utility of an API is diminished if it's not straightforward to invoke. BentoML 1.2 introduces enhancements to the BentoClient, streamlining the process of calling Service endpoints developed using BentoML. With the provision of a Service endpoint, developers have the flexibility to opt for either a synchronous or asynchronous client, tailored to their specific requirements. BentoClient offers a Pythonic way to invoke the Service endpoint, allowing parameters to be supplied in native Python format, letting the client efficiently handles the necessary serialization while ensuring compatibility and performance.
from pathlib import Path with bentoml.SyncHTTPClient('http://localhost:3000') as client: file_path = Path('/path/to/your/file') response = client.generate(img=file_path) print(response)
Real-world examples
The BentoML open source community consists of some of the most smart and creative developers. We've learned that the best way to showcase what BentoML can do is not through dry, conceptual documentation but through real-world examples. While we will still keep our documentation on core concepts up to date and of high quality, we will focus on publishing actual examples from the real world. These examples will demonstrate the latest models that work right out of the box and the best practices for running them. Developers can easily deploy these example projects or fork them to add their own customizations. Check out our current list of examples, and we'll continue to publish new ones to the gallery as exciting new models are released.
Conclusion
We can’t wait for you to get started and explore the exciting list of new features. Along with all the familiar features that our developers trust and love, such as adaptive batching, Bento packaging and containerization, and observability, we hope that BentoML 1.2 will empower you with the freedom to build amazing things.
More on BentoML
To learn more about BentoML, check out the following resources:
- [Blog] Deploying Stable Diffusion XL with Latent Consistency Model LoRAs on BentoCloud
- [Blog] Deploying A Text-To-Speech Application with BentoML
- [Blog] Deploying An Image Captioning Server With BentoML
- [Blog] BYOC to BentoCloud: Privacy, Flexibility, and Cost Efficiency in One Package
- Try BentoCloud and get $30 in free credits on signup! Experience a serverless platform tailored to simplify the building and management of your AI applications, ensuring both ease of use and scalability.