Deploying Stable Diffusion XL with Latent Consistency Model LoRAs on BentoCloud
February 28, 2024 • Written By Sherlock Xu
Latent Consistency Models (LCM) can be used to streamline the image generation process, particularly for models like Stable Diffusion (SD) and SDXL. In this Hugging Face blog post, the authors introduced a new way of integrating LCM LoRAs into SDXL, which allows the model to achieve high-quality inference in just 2 to 8 steps, a significant reduction from its original requirement. This adaptation, or LCM LoRA, represents a universal acceleration module for SD models, making the inference process faster and more accessible.
In this blog post, I will talk about how to wrap SDXL with LCM LoRAs into a BentoML Service and deploy it on BentoCloud. This allows you to better run and manage an image generation application in production.
Before you begin
The source code of this image generation application powered by SDXL with LCM LoRAs is stored in the BentoLCM repo. Clone it and install all the required packages.
git clone https://github.com/bentoml/BentoLCM.git cd BentoLCM pip install -r requirements.txt
Note that this project uses BentoML 1.2.
Defining a BentoML Service
The key of wrapping the SDXL model and LCM LoRAs with BentoML is to create a BentoML Service. By convention, it is defined in a service.py file.
First, import the necessary libraries. Add these lines at the top of the service.py file:
import bentoml from PIL.Image import Image # For handling images generated by SDXL
Specify the models to use. As mentioned above, we are using an SDXL model and an LCM LoRA. In addition, set a sample prompt so that we can test the application later:
model_id = "stabilityai/stable-diffusion-xl-base-1.0" lcm_lora_id = "latent-consistency/lcm-lora-sdxl" sample_prompt = "close-up photography of old man standing in the rain at night, in a street lit by lamps, leica 35mm summilux"
Now, let's define a BentoML Service called LatentConsistency. It loads the models and defines an API endpoint for generating images based on text prompts.
Begin by defining a Python class and its constructor. Starting from BentoML 1.2, we use the @bentoml.service decorator to mark a Python class as a BentoML Service. As the application will be deployed on BentoCloud later, set configurations like resources to specify the GPU to use on BentoCloud.
# Annotate the class as a BentoML Service with the decorator @bentoml.service( traffic={"timeout": 300}, workers=1, resources={ "gpu": 1, "gpu_type": "nvidia-l4", }, ) class LatentConsistency: def __init__(self) -> None: from diffusers import DiffusionPipeline, LCMScheduler import torch # Load the text-to-image model and the LCM LoRA weights self.lcm_txt2img = DiffusionPipeline.from_pretrained( model_id, torch_dtype=torch.float16, variant="fp16", ) self.lcm_txt2img.load_lora_weights(lcm_lora_id) # Change the scheduler to the LCMScheduler self.lcm_txt2img.scheduler = LCMScheduler.from_config(self.lcm_txt2img.scheduler.config) # Move the model to the GPU for faster inference self.lcm_txt2img.to(device="cuda", dtype=torch.float16)
Next, define an API endpoint in your class that takes a text prompt and generates an image:
@bentoml.api def txt2img( self, prompt: str = sample_prompt, num_inference_steps: int = 4, guidance_scale: float = 1.0, ) -> Image: image = self.lcm_txt2img( prompt=prompt, num_inference_steps=num_inference_steps, guidance_scale=guidance_scale, ).images[0] return image
This function defines an endpoint txt2img that accepts a prompt, number of inference steps, and a guidance scale. It uses Python type annotations to specify the types of parameters it expects and the type of value it returns. The values specified in the code are the defaults provided to users. The returned image is a Path object.
Note that this example uses 4 inference steps to generate images. This parameter impacts the quality and generation time of the resulting image. See this Hugging Face blog post to learn more.
That’s all! Here is the complete Service code in service.py for your reference (available in the repo cloned):
import bentoml from PIL.Image import Image model_id = "stabilityai/stable-diffusion-xl-base-1.0" lcm_lora_id = "latent-consistency/lcm-lora-sdxl" sample_prompt = "close-up photography of old man standing in the rain at night, in a street lit by lamps, leica 35mm summilux" @bentoml.service( traffic={"timeout": 300}, workers=1, resources={ "gpu": 1, "gpu_type": "nvidia-l4", }, ) class LatentConsistency: def __init__(self) -> None: from diffusers import DiffusionPipeline, LCMScheduler import torch self.lcm_txt2img = DiffusionPipeline.from_pretrained( model_id, torch_dtype=torch.float16, variant="fp16", ) self.lcm_txt2img.load_lora_weights(lcm_lora_id) self.lcm_txt2img.scheduler = LCMScheduler.from_config(self.lcm_txt2img.scheduler.config) self.lcm_txt2img.to(device="cuda", dtype=torch.float16) @bentoml.api def txt2img( self, prompt: str = sample_prompt, num_inference_steps: int = 4, guidance_scale: float = 1.0, ) -> Image: image = self.lcm_txt2img( prompt=prompt, num_inference_steps=num_inference_steps, guidance_scale=guidance_scale, ).images[0] return image
Before deploying, let’s test this Service locally using the BentoML CLI.
bentoml serve service:LatentConsistency
The command starts the Service at http://localhost:3000. You can interact with it using the Swagger UI. Alternatively, create a BentoML client as below. As the response is a Path object, you can specify a custom directory to save the image.
import bentoml from pathlib import Path with bentoml.SyncHTTPClient("http://localhost:3000") as client: result_path = client.txt2img( guidance_scale=1, num_inference_steps=4, prompt="close-up photography of old man standing in the rain at night, in a street lit by lamps, leica 35mm summilux", ) destination_path = Path("/path/to/save/image.png") result_path.rename(destination_path)
An example image returned:
Deploying to BentoCloud
BentoCloud provides the underlying infrastructure optimized for running and managing AI applications on the cloud. To deploy this project to BentoCloud, make sure you have logged in, then run bentoml deploy in the cloned repo. I added the --scaling-min and --scaling-max flags here to tell BentoCloud the scaling limits of this Deployment, which means it will be scaled within this range according to the traffic received.
bentoml deploy . --scaling-min 1 --scaling-max 3
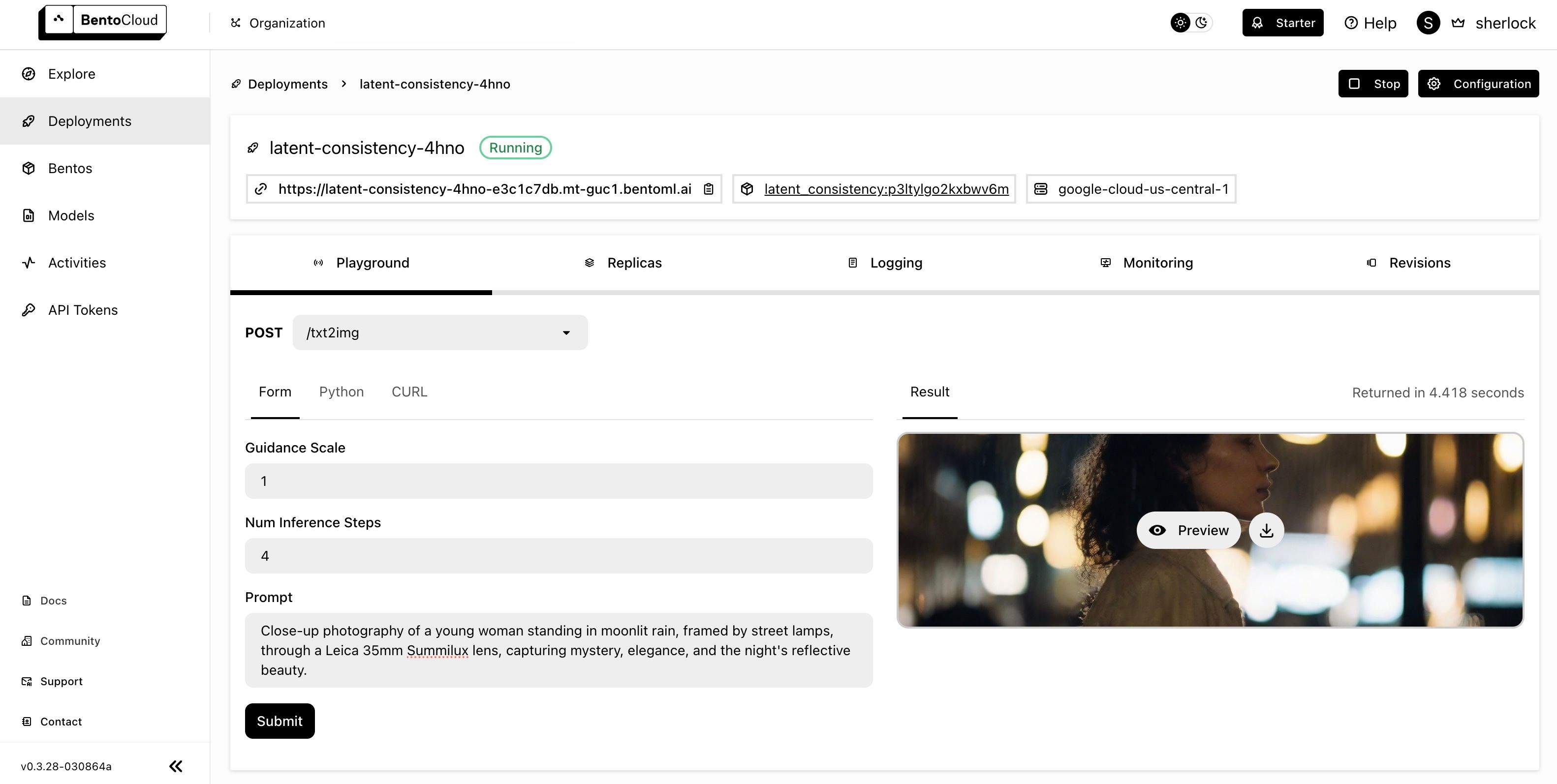
After the Deployment is ready, visit its details page on the BentoCloud console and interact with it on the Playground tab. This time I changed the prompt as below:

The generated image can be previewed or downloaded.
Conclusion
By wrapping an SDXL model enhanced with LCM LoRA in a BentoML Service, you can rapidly deploy efficient, high-quality image generation AI applications. While the LCM LoRA improves computational efficiency, BentoCloud helps streamline deployment and scaling, ensuring that your application remains responsive regardless of demand.
In future blog posts, we will see more production-ready AI projects deployed with BentoML and BentoCloud. Happy coding ⌨️!
More on BentoML
To learn more about BentoML, check out the following resources:
- [Blog] Introducing BentoML 1.2
- [Blog] Deploying A Text-To-Speech Application with BentoML
- [Blog] Deploying An Image Captioning Server With BentoML
- [Blog] BYOC to BentoCloud: Privacy, Flexibility, and Cost Efficiency in One Package
- Try BentoCloud and get $30 in free credits on signup! Experience a serverless platform tailored to simplify the building and management of your AI applications, ensuring both ease of use and scalability.