Deploying A Large Language Model with BentoML and vLLM
March 14, 2024 • Written By Sherlock Xu
Large language models (LLMs) promise to redefine our interaction with technology across various industries. Yet, the leap from the promise of LLMs to their practical application presents a significant hurdle. The challenge lies not just in developing and training them, but in serving and deploying them efficiently and cost-effectively.
In previous blog posts, we delved into using BentoCloud for deploying ML servers, showcasing its ability to offer serverless infrastructure tailored for optimal cost efficiency. Upon this foundation, we can integrate a new tool to enhance our BentoML Service for better LLM inference and serving: vLLM.
In this blog post, let’s see how we can create an LLM server built with vLLM and BentoML, and deploy it in production with BentoCloud. By the end of this tutorial, you will have an interactive AI assistant as below:
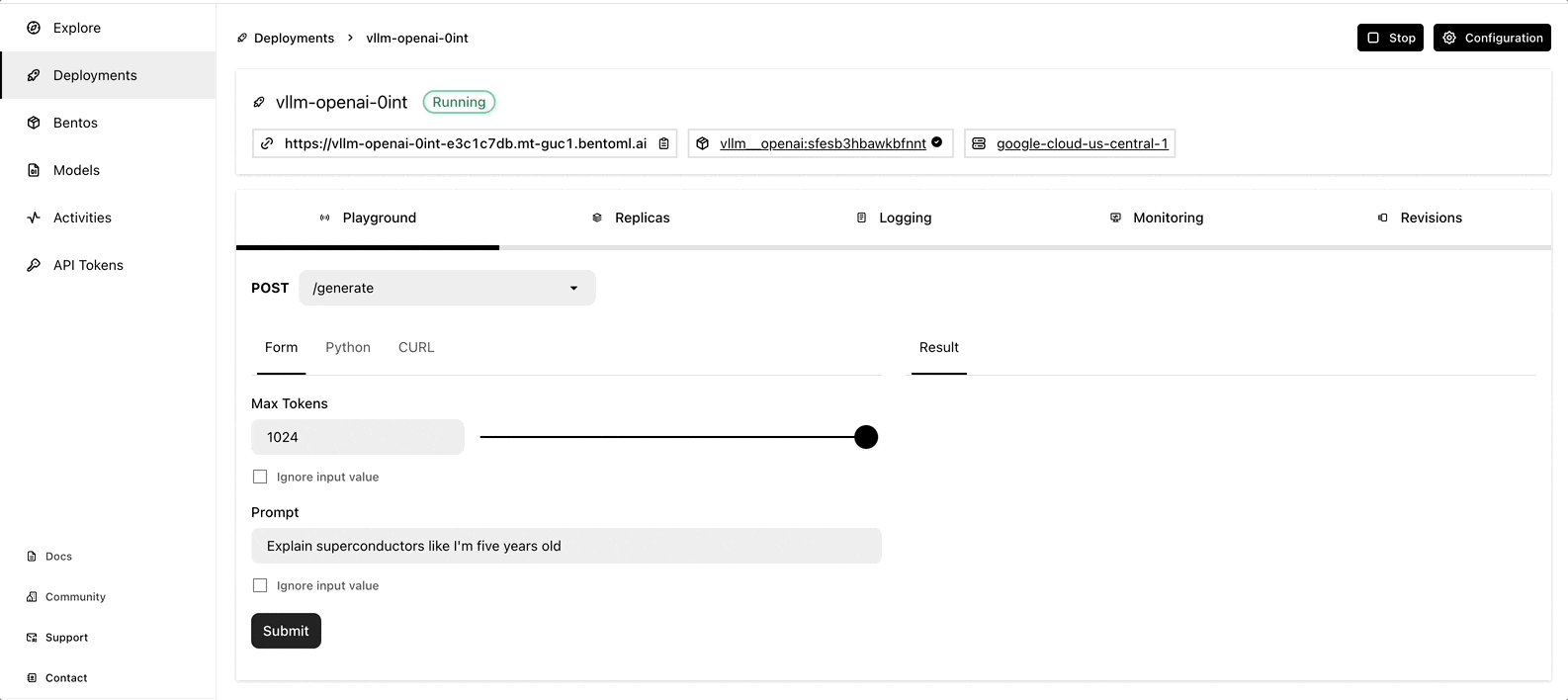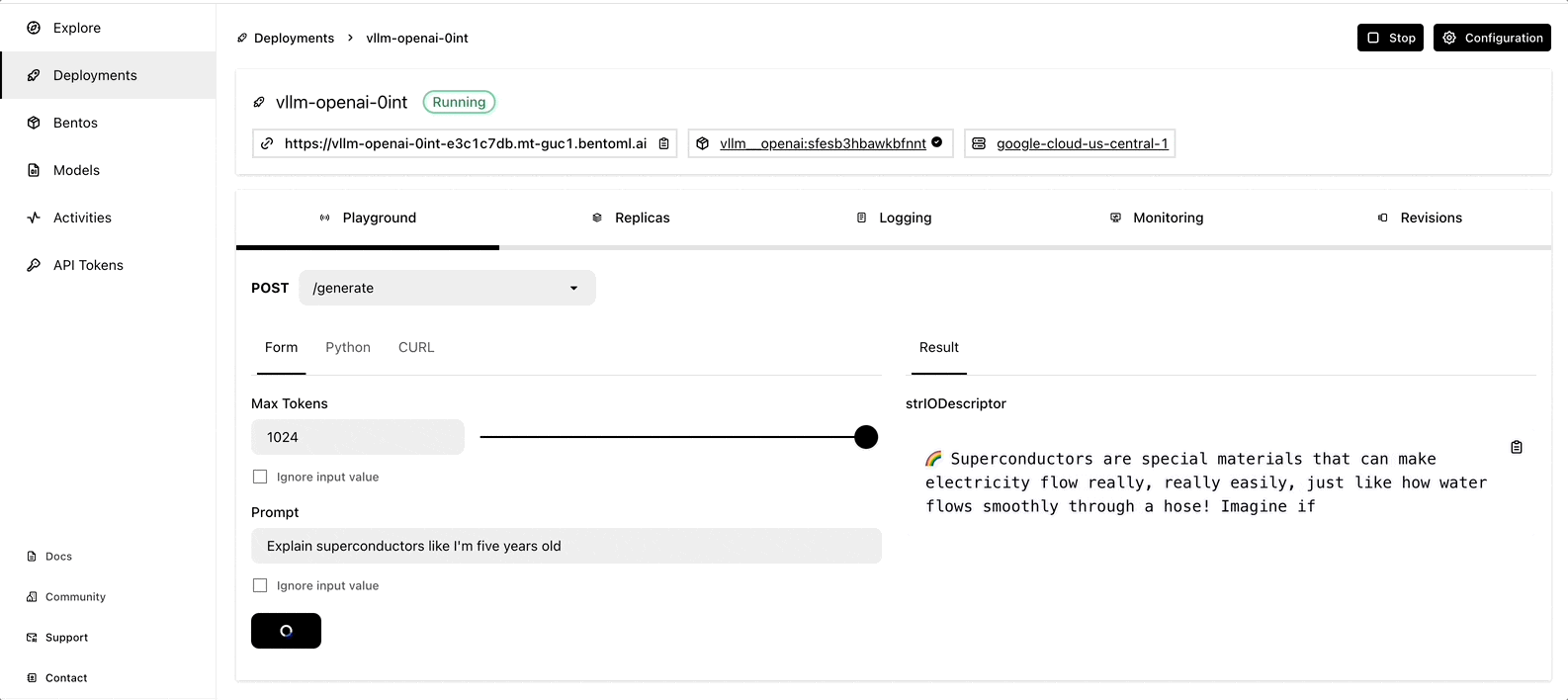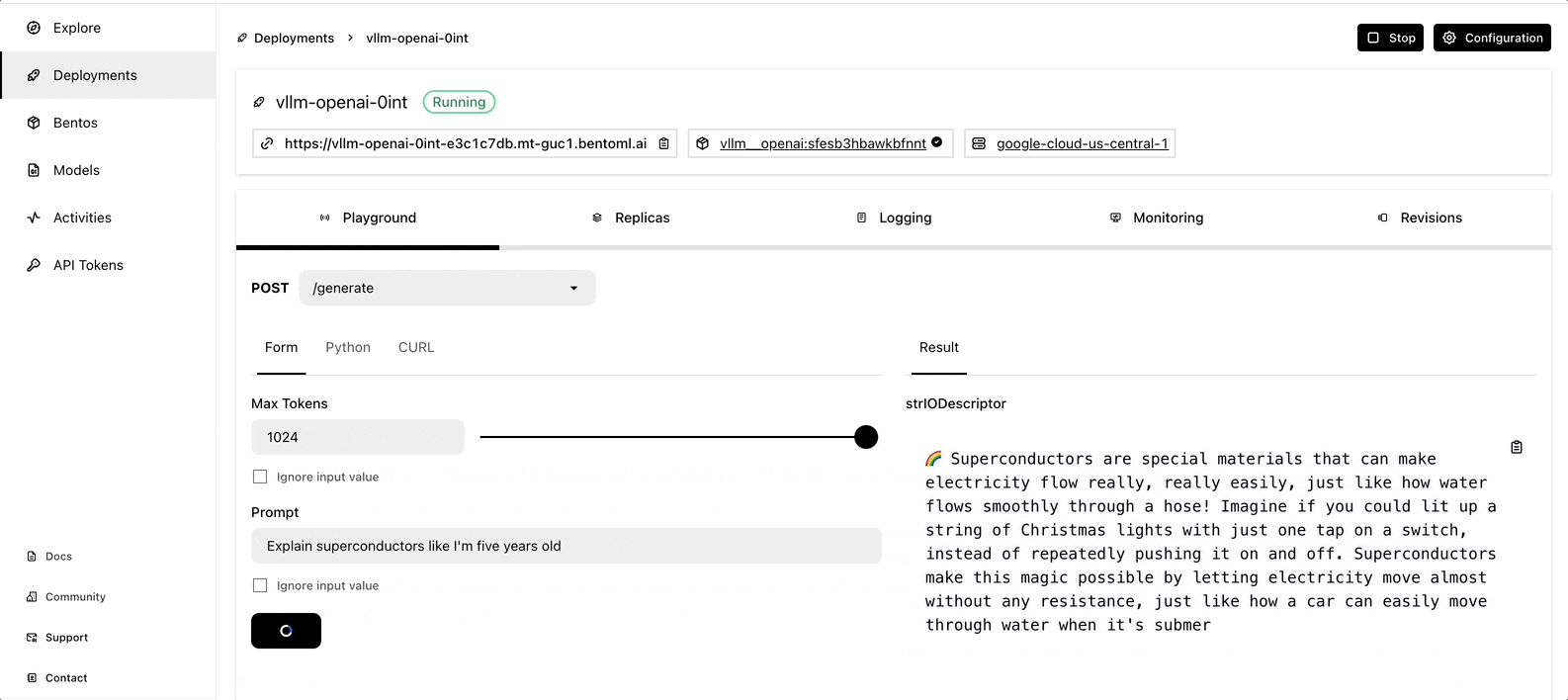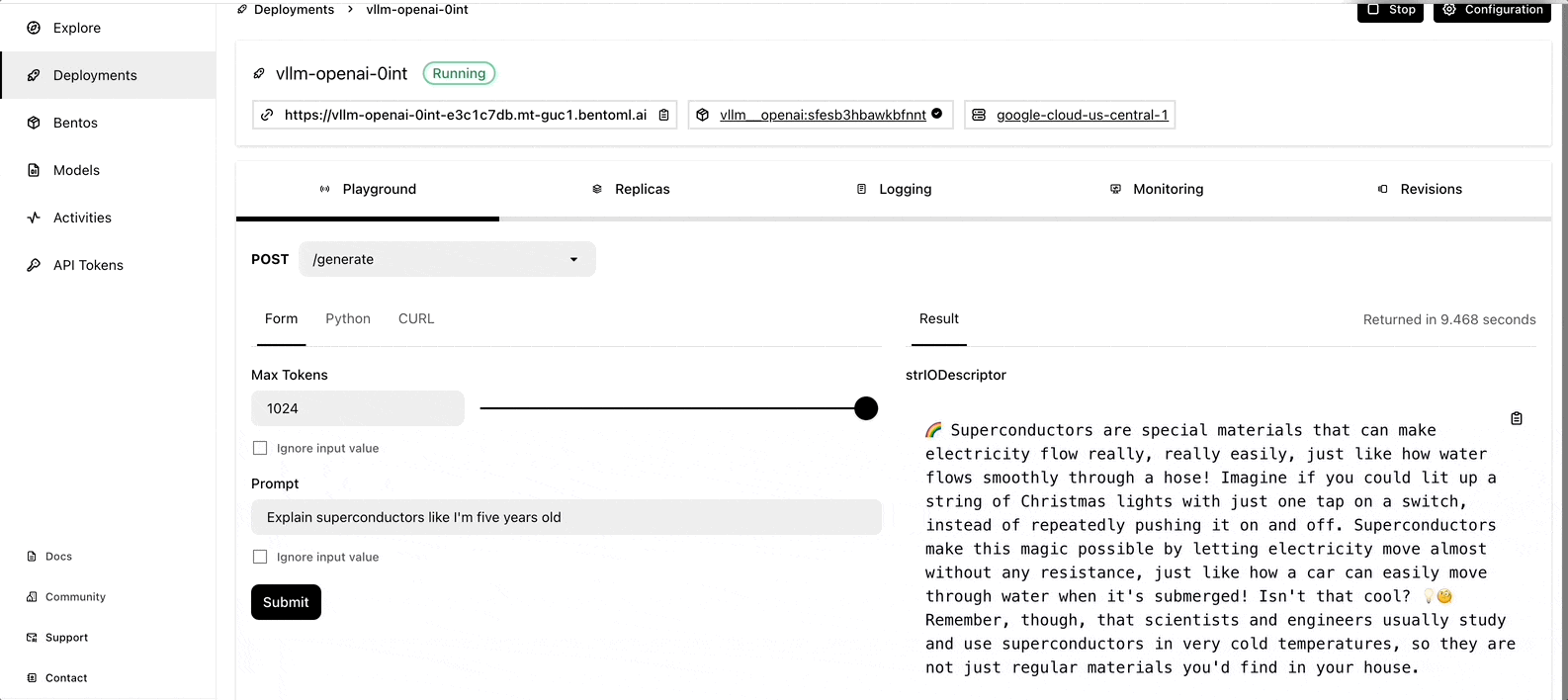
What is vLLM?
vLLM is a fast and easy-to-use open-source library for LLM inference and serving. Developed by the minds at UC Berkeley and deployed at Chatbot Arena and Vicuna Demo, vLLM is equipped with an arsenal of features. To name a few:
- Dramatic performance boost: vLLM leverages PagedAttention to achieve up to 24x higher throughput than Hugging Face Transformers, making LLM serving faster and more efficient.
- Ease of use: Designed for straightforward integration, vLLM simplifies the deployment of LLMs with an easy-to-use interface.
- Cost-effective: Optimizes resource use, significantly lowering the computational cost and making LLM deployment accessible even for teams with limited compute resources.
See this article vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention to learn more about vLLM.
Setting up the environment
As always, I suggest you set up a virtual environment for your project to keep your dependencies organized:
python -m venv vllm-bentoml-env source vllm-bentoml-env/bin/activate
Then, clone the project’s repo and install all the required dependencies.
git clone https://github.com/bentoml/BentoVLLM.git cd BentoVLLM pip install -r requirements.txt && pip install -f -U "pydantic>=2.0"
The stage is now set. Let's get started!
Defining a BentoML Service
-
Create a BentoML Service file
service.py(already available in the repo you cloned) and open it in your preferred text editor. We'll start by importing necessary modules:import uuid from typing import AsyncGenerator import bentoml from annotated_types import Ge, Le from typing_extensions import Annotated from bentovllm_openai.utils import openai_endpointsThese imports are for asynchronous operations, type checking, and the integration of BentoML and vLLM-specific functionalities. You will know more about them in the following sections.
-
Next, specify the model to use and set some ground rules for it. For this project, I will use
mistralai/Mistral-7B-Instruct-v0.2, which is reported to have outperformed the Llama 2 13B model in all the benchmark tests. You can choose any other model supported by vLLM.Also, set the maximum token limit for the model's responses and use a template for our prompts. This template is like a script for how we want our model to behave - polite, respectful, and safe:
MODEL_ID = "mistralai/Mistral-7B-Instruct-v0.2" MAX_TOKENS = 1024 PROMPT_TEMPLATE = """<s>[INST] You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature. If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information. {user_prompt} [/INST] """ -
Now we can begin to design the BentoML Service. Starting from BentoML 1.2, we use the
@bentoml.servicedecorator to mark a Python class as a BentoML Service. Additional configurations liketimeoutcan be set to customize its runtime behavior. Theresourcesfield specifies the GPU requirements as we will deploy this Service on BentoCloud later; cloud instances will be provisioned based on it.In addition, use the
@openai_endpointsdecorator frombentovllm_openai.utils(available here) to set up OpenAI-compatible endpoints. This is like giving the Service a universal adapter, allowing it to interact with various clients as if it were an OpenAI service itself.@openai_endpoints(served_model=MODEL_ID) @bentoml.service( traffic={ "timeout": 300, }, resources={ "gpu": 1, "gpu_type": "nvidia-l4", }, ) class VLLM: -
Within the class, set an LLM engine by specifying the model and how many tokens it should generate. Read the vLLM documentation to learn more about the modules imported here.
class VLLM: def __init__(self) -> None: from vllm import AsyncEngineArgs, AsyncLLMEngine ENGINE_ARGS = AsyncEngineArgs( model=MODEL_ID, max_model_len=MAX_TOKENS ) self.engine = AsyncLLMEngine.from_engine_args(ENGINE_ARGS) -
To interact with this Service, define an API method using
@bentoml.api. It serves as the primary interface for processing input prompts and streaming back generated text.@bentoml.api async def generate( self, # Accept a prompt with a default value; users can override this when calling the API prompt: str = "Explain superconductors like I'm five years old", # Enforce the generated response to be within a specified range using type annotations max_tokens: Annotated[int, Ge(128), Le(MAX_TOKENS)] = MAX_TOKENS, ) -> AsyncGenerator[str, None]: from vllm import SamplingParams # Initialize the parameters for sampling responses from the LLM (maximum token in this case) SAMPLING_PARAM = SamplingParams(max_tokens=max_tokens) # Format the user's prompt with the predefined prompt template prompt = PROMPT_TEMPLATE.format(user_prompt=prompt) # Send the formatted prompt to the LLM engine asynchronously stream = await self.engine.add_request(uuid.uuid4().hex, prompt, SAMPLING_PARAM) # Initialize a cursor to track the portion of the text already returned to the user cursor = 0 async for request_output in stream: # Extract text from the first output text = request_output.outputs[0].text yield text[cursor:] cursor = len(text)
That’s all the code! To run this project with bentoml serve, you need a NVIDIA GPU with at least 16G VRAM.
bentoml serve .
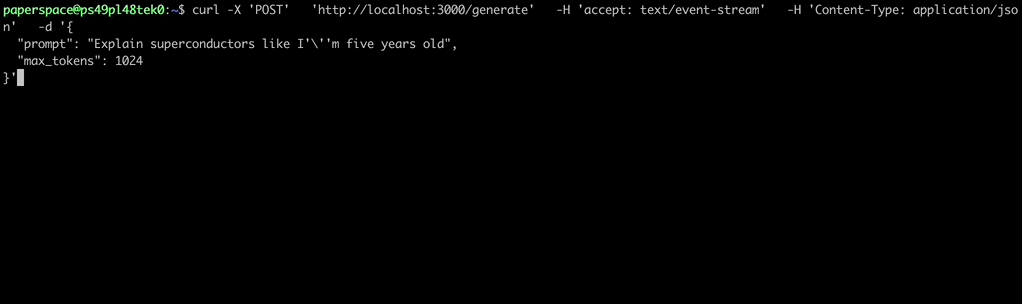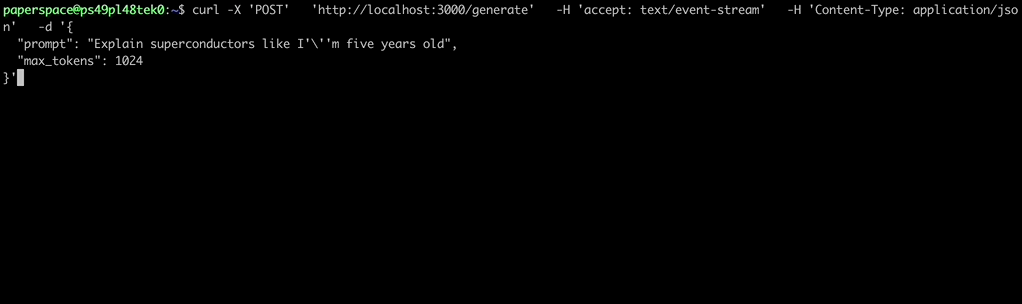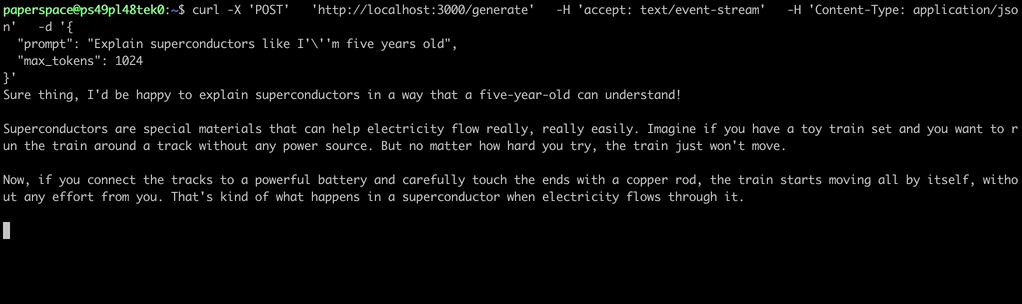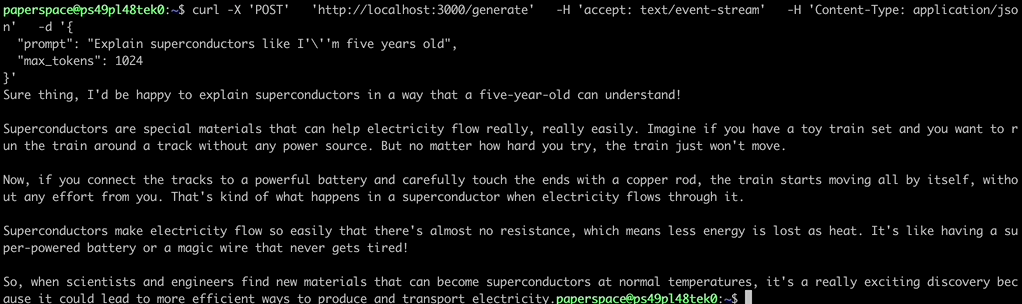
The server will be active at http://localhost:3000. You can communicate with it by using the curl command:
curl -X 'POST' \ 'http://localhost:3000/generate' \ -H 'accept: text/event-stream' \ -H 'Content-Type: application/json' \ -d '{ "prompt": "Explain superconductors like I'\''m five years old", "max_tokens": 1024 }'
Deploying the LLM to BentoCloud
Deploying LLMs in production often requires significant computational resources, particularly GPUs, which may not be readily available on local machines. Therefore, you can use BentoCloud, a platform designed to simplify the deployment, management, and scaling of machine learning models, including those as resource-intensive as LLMs.
Before you can deploy this LLM to BentoCloud, you'll need to:
- Sign up: If you haven't already, create an account on BentoCloud for free. Navigate to the BentoCloud website and follow the sign-up process.
- Log in: Once your account is set up, log in to BentoCloud.
With your BentoCloud account ready, navigate to your project's directory where bentofile.yaml is stored (it is already available in the repo you cloned), then run:
bentoml deploy .
The deployment may take some time. When it is complete, you can interact with the LLM server on the BentoCloud console.
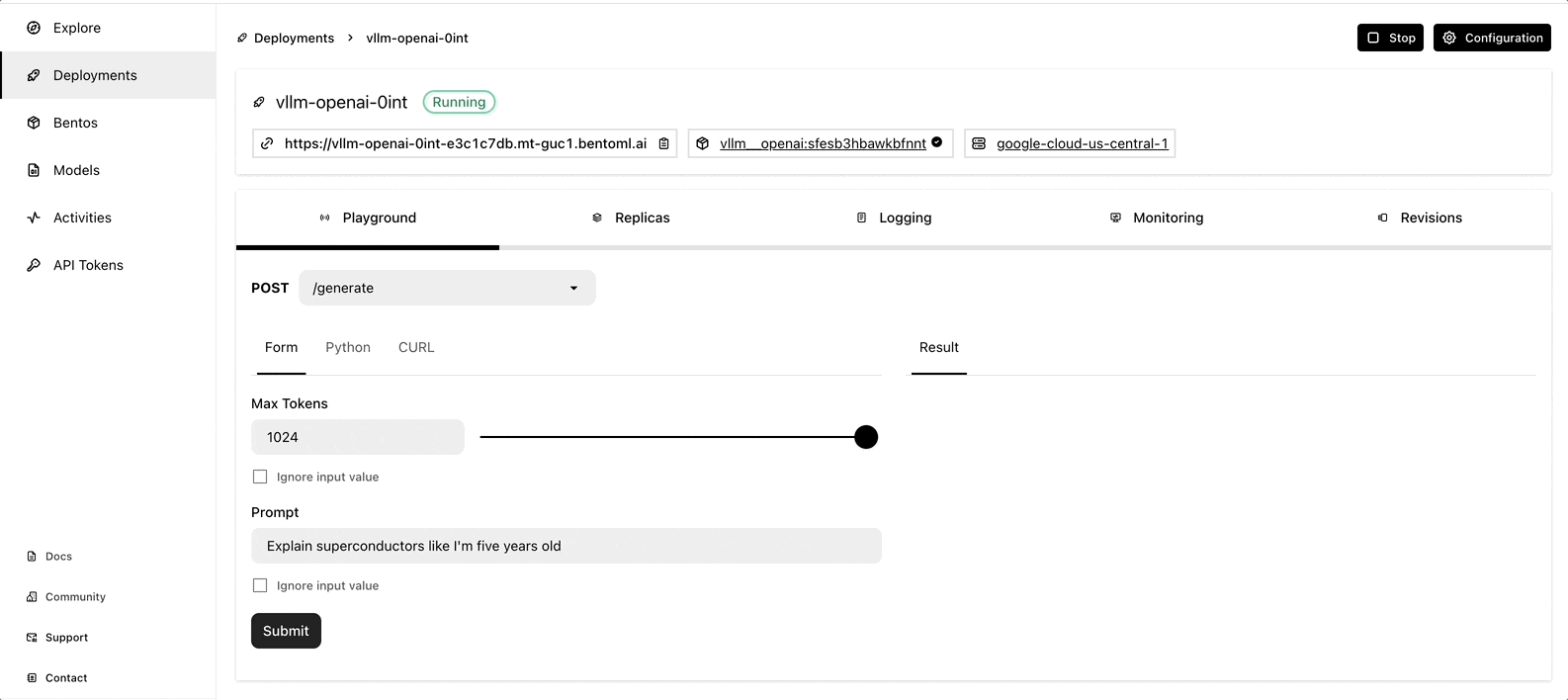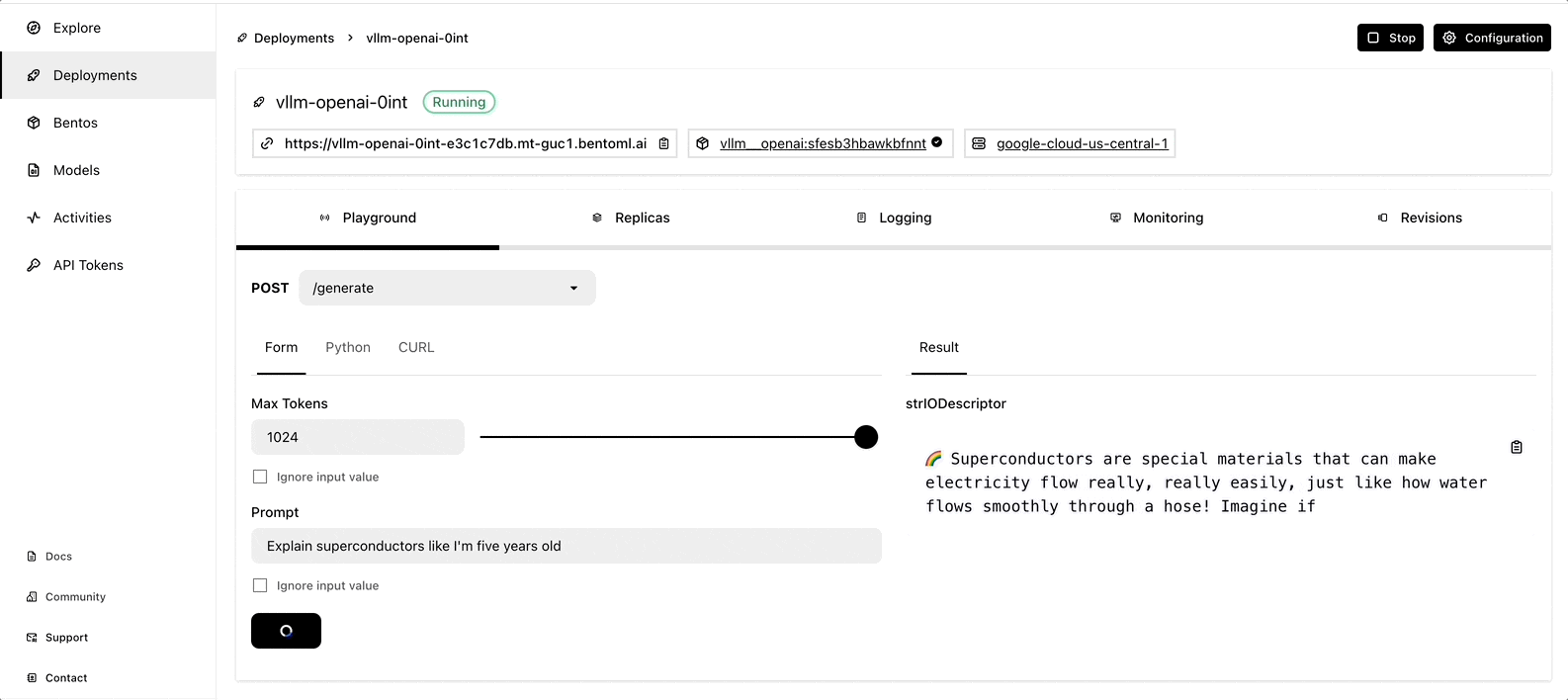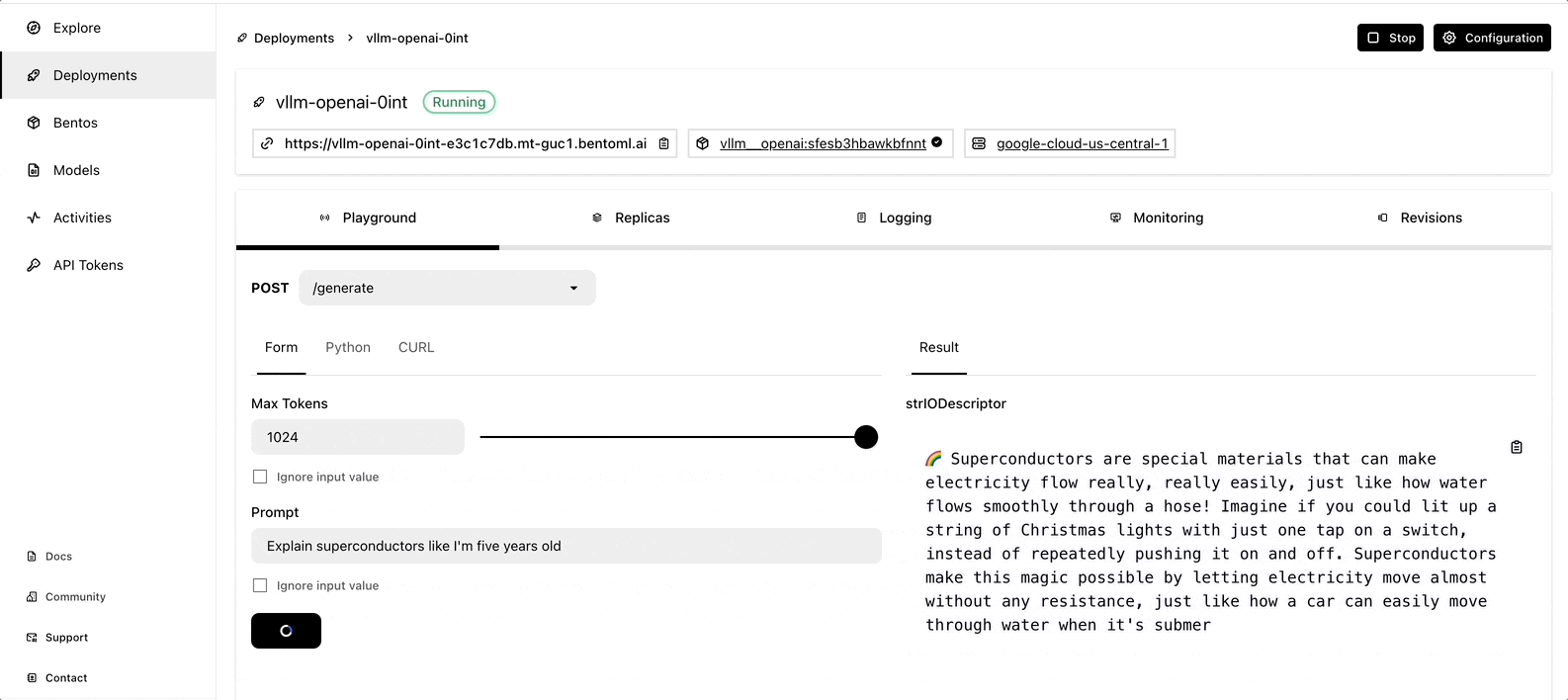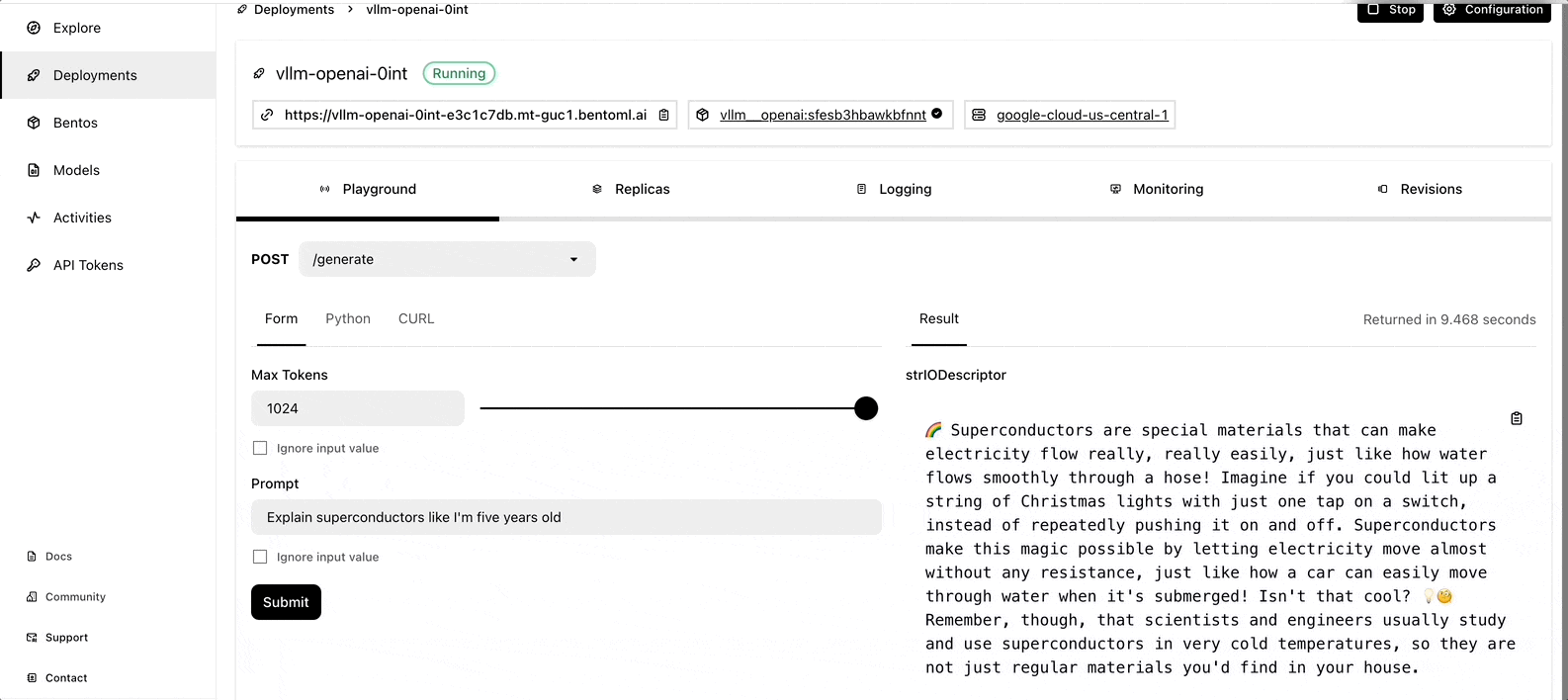
More on BentoML and vLLM
To learn more about BentoML and vLLM, check out the following resources:
- [Doc] vLLM documentation
- [Doc] vLLM inference
- [Blog] Introducing BentoML 1.2
- [Blog] Deploying A Text-To-Speech Application with BentoML
- [Blog] Deploying An Image Captioning Server With BentoML
- Try BentoCloud and get $30 in free credits on signup! Experience a serverless platform tailored to simplify the building and management of your AI applications, ensuring both ease of use and scalability.